
PostgreSQL 10 - Réplication logique
jeu. 26 avril 2018 (PostgreSQL)Cet article est issu de ma conférence au PG Session 2017.
Une vidéo est même disponible.
Plan
- Petit rappel sur la réplication physique
- Qu'est-ce que la réplication logique ?
- Fonctionnement
- Limitations
- Exemples
Réplication physique
- Réplication de toute l'instance
- au niveau bloc
- par rejeu des journaux de transactions
- Quelques limitations :
- intégralité de l’instance
- même architecture (x86, ARM…)
- même version majeure
- pas de requête en écriture sur le secondaire
Dans le cas de la réplication dite « physique », le moteur ne réplique pas les requêtes, mais le résultat de celles-ci, et plus précisément les modifications des blocs de données. Le serveur secondaire se contente de rejouer les journaux de transaction.
Cela impose certaines limitations. Les journaux de transactions ne contenant comme information que le nom des fichiers (et pas les noms et / ou type des objets SQL impliqués), il n'est pas possible de ne rejouer qu'une partie. De ce fait, on réplique l'intégralité de l'instance.
La façon dont les données sont codées dans les fichiers dépend de l'architecture matérielle (32 / 64 bits, little / big endian) et des composants logiciels du système d'exploitation (tri des données, pour les index). De ceci, il en découle que chaque instance du cluster de réplication doit fonctionner sur un matériel dont l'architecture est identique à celle des autres instances et sur un système d'exploitation qui trie les données de la même façon.
Les versions majeures ne codent pas forcément les données de la même façon, notamment dans les journaux de transactions. Chaque instance du cluster de réplication doit donc être de la même version majeure.
Enfin, les serveurs secondaires sont en lecture seule. Cela signifie (et c'est bien) qu'on ne peut pas insérer / modifier / supprimer de données sur les tables répliquées. Mais on ne peut pas non plus ajouter des index supplémentaires ou des tables de travail, ce qui est bien dommage dans certains cas.
Réplication logique - Principe
- Réutilisation de l'infrastructure existante
- réplication en flux
- slots de réplication
- Réplique les changements sur une seule base de données
- d'un ensemble de tables défini
- Uniquement INSERT / UPDATE / DELETE
- pas les DDL, ni les TRUNCATE
Contrairement à la réplication physique, la réplication logique ne réplique pas les blocs de données. Elle décode le résultat des requêtes qui est transmis au secondaire. Celui-ci applique les modifications SQL issues du flux de réplication logique.
La réplication logique utilise un système de publication / abonnement avec un ou plusieurs abonnés qui s'abonnent à une ou plusieurs publications d'un nœud particulier.
Une publication peut être définie sur n'importe quel serveur primaire de réplication physique. Le nœud sur laquelle la publication est définie est nommé éditeur. Le nœud où un abonnement a été défini est nommé abonné.
Une publication est un ensemble de modifications généré par une table ou un groupe de table. Chaque publication existe au sein d'une seule base de données.
Un abonnement définit la connexion à une autre base de données et un ensemble de publications (une ou plus) auxquelles l'abonné veut souscrire.
Fonctionnement

Schéma obtenu sur blog.anayrat.info.
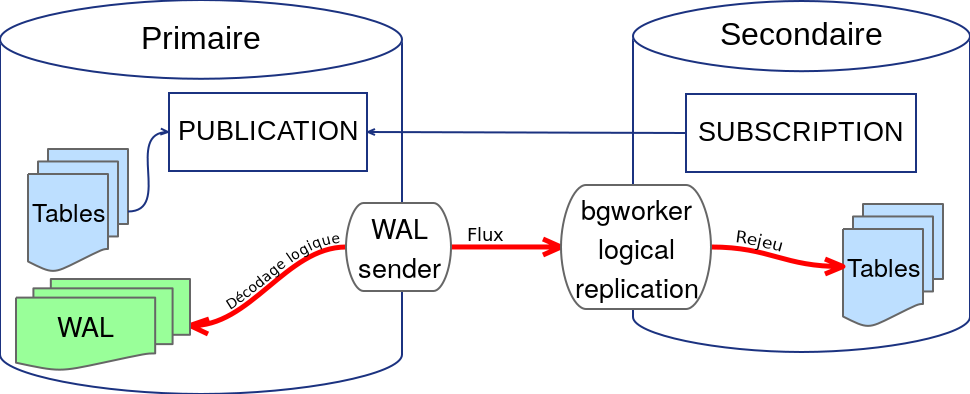{kind=link}
Source : Adrien Nayrat - Série sur la réplication logique
- Une publication est créée sur le serveur éditeur
- L'abonné souscrit à cette publication, c’est un « souscripteur »
- Un processus spécial est lancé : le « bgworker logical replication ». Il va se connecter à un slot de réplication sur le serveur éditeur
- Le serveur éditeur va procéder à un décodage logique des journaux de transaction pour extraire les résultats des ordres SQL
- Le flux logique est transmis à l'abonné qui l'applique sur les tables
Limitations
-
Non répliqué :
- Schéma
- Séquences
- Large objects
-
Pas de publication des tables parents du partitionnement
- Ne convient pas comme fail-over
- Contrainte d'unicité nécessaire pour
UPDATEetDELETE
Le schéma de la base de données ainsi que les commandes DDL ne sont pas
répliquées, y compris l'ordre TRUNCATE. Le schéma initial peut être créé en
utilisant par exemple pg_dump --schema-only. Il faudra dès lors répliquer
manuellement les changements de structure.
Il n'est pas obligatoire de conserver strictement la même structure des deux côtés. Afin de conserver sa cohérence, la réplication s'arrêtera en cas de conflit.
Il est d'ailleurs nécessaire d'avoir des contraintes de type PRIMARY KEY ou
UNIQUE et NOT NULL pour permettre la propagation des ordres UPDATE et
DELETE.
Les triggers des tables abonnées ne seront pas déclenchés par les modifications reçues via la réplication.
En cas d'utilisation du partitionnement, il n'est pas possible d'ajouter des tables parents dans la publication.
Les séquences et large objects ne sont pas répliqués.
De manière générale, il serait possible d'utiliser la réplication logique en cas de fail-over en propageant manuellement les mises à jour de séquences et de schéma. La réplication physique est cependant plus appropriée pour cela.
La réplication logique vise d'autres objectifs, tels que la génération de rapports ou la mise à jour de version majeure de PostgreSQL.
Démo réplication logique : publication
Nous allons créer une base de donnée souscription et y répliquer de façon
logique la table partitionnée meteo créée précédemment.
Tout d'abord, nous devons nous assurer que notre instance est configurée pour
permettre la réplication logique. Le paramètre wal_level doit être fixé à
logical dans le fichier postgresql.conf.
Ce paramètre a un impact sur les informations stockées dans les fichiers WAL, un
redémarrage de l'instance est donc nécessaire en cas de changement.
Ensuite, créons la base de donnée souscription dans notre instance 10 :
psql -c "CREATE DATABASE souscription"
Dans la base de données pg10, nous allons tenter de créer la publication
sur la table partitionnée :
pg10=# CREATE PUBLICATION local_publication FOR TABLE meteo;
ERROR: "meteo" is a partitioned table
DÉTAIL : Adding partitioned tables to publications is not supported.
ASTUCE : You can add the table partitions individually.
Comme précisé dans le cours, il est impossible de publier les tables parents. Nous allons devoir publier chaque partition. Nous partons du principe que seul le mois de septembre nous intéresse :
CREATE PUBLICATION local_publication FOR TABLE
meteo_lyon_201709, meteo_nantes_201709, meteo_paris_201709;
SELECT * FROM pg_create_logical_replication_slot('local_souscription','pgoutput');
Comme nous travaillons en local, il est nécessaire de créer le slot de réplication manuellement. Il faudra créer la souscription de manière à ce qu'elle utilise le slot de réplication que nous venons de créer. Si ce n'est pas fait, nous nous exposons à un blocage de l'ordre de création de souscription. Ce problème n'arrive pas lorsque l'on travaille sur deux instances séparées.
Démo réplication logique : souscription
Après avoir géré la partie publication, passons à la partie souscription.
Nous allons maintenant créer un utilisateur spécifique qui assurera la réplication logique :
$ createuser --replication replilogique
Lui donner un mot de passe et lui permettre de visualiser les données dans la
base pg10 :
pg10=# ALTER ROLE replilogique PASSWORD 'pwd';
ALTER ROLE
pg10=# GRANT SELECT ON ALL TABLES IN SCHEMA public TO replilogique;
GRANT
Nous devons également lui autoriser l'accès dans le fichier pg_hba.conf de
l'instance :
host all replilogique 127.0.0.1/32 md5
Sans oublier de recharger la configuration :
pg10=# SELECT pg_reload_conf();
pg_reload_conf
----------------
t
(1 ligne)
Dans la base de données souscription, créer les tables à répliquer :
CREATE TABLE meteo (
t_id integer GENERATED BY DEFAULT AS IDENTITY,
lieu text NOT NULL,
heure_mesure timestamp DEFAULT now(),
temperature real NOT NULL
) PARTITION BY RANGE (lieu, heure_mesure);
CREATE TABLE meteo_lyon_201709 PARTITION of meteo FOR VALUES
FROM ('Lyon', '2017-09-01 00:00:00') TO ('Lyon', '2017-10-01 00:00:00');
CREATE TABLE meteo_nantes_201709 PARTITION of meteo FOR VALUES
FROM ('Nantes', '2017-09-01 00:00:00') TO ('Nantes', '2017-10-01 00:00:00');
CREATE TABLE meteo_paris_201709 PARTITION of meteo FOR VALUES
FROM ('Paris', '2017-09-01 00:00:00') TO ('Paris', '2017-10-01 00:00:00');
Nous pouvons maintenant créer la souscription à partir de la base de donnée
souscription :
souscription=# CREATE SUBSCRIPTION souscription
CONNECTION 'host=127.0.0.1 port=5432 user=replilogique dbname=pg10 password=pwd'
PUBLICATION local_publication with (create_slot=false,slot_name='local_souscription');
CREATE SUBSCRIPTION
Vérifier que les données ont bien été répliquées sur la base souscription.
N'hésitez pas à vérifier dans les logs dans le cas où une opération ne semble pas fonctionner.
Démo réplication logique : modification des données
Maintenant que la réplication logique est établie, nous allons étudier les possibilités offertes par cette dernière.
Contrairement à la réplication physique, il est possible de modifier les données de l'instance en souscription :
souscription=# SELECT * FROM meteo WHERE t_id=1;
t_id | lieu | heure_mesure | temperature
------+------+---------------------+-------------
1 | Lyon | 2017-09-24 04:10:59 | 18.59
(1 ligne)
souscription=# DELETE FROM meteo WHERE t_id=1;
DELETE 1
souscription=# SELECT * FROM meteo WHERE t_id=1;
t_id | lieu | heure_mesure | temperature
------+------+--------------+-------------
(0 ligne)
Cette suppression n'a pas eu d'impact sur l'instance principale :
pg10=# SELECT * FROM meteo WHERE t_id=1;
t_id | lieu | heure_mesure | temperature
------+------+---------------------+-------------
1 | Lyon | 2017-09-24 04:10:59 | 18.59
(1 ligne)
Essayons maintenant de supprimer ou modifier des données de l'instance principale :
pg10=# UPDATE meteo SET temperature=25 WHERE temperature<15;
ERROR: cannot update table "meteo_lyon_201709" because it does not have
replica identity and publishes updates
ASTUCE : To enable updating the table, set REPLICA IDENTITY using ALTER TABLE.
pg10=# DELETE FROM meteo WHERE temperature < 15;
ERROR: cannot delete from table "meteo_lyon_201709" because it does not have
replica identity and publishes deletes
ASTUCE : To enable deleting from the table, set REPLICA IDENTITY using ALTER TABLE.
Il nous faut créer un index unique sur les tables répliquées puis déclarer cet
index comme REPLICA IDENTITY dans la base de donnée pg10 :
CREATE UNIQUE INDEX meteo_lyon_201709_pkey ON meteo_lyon_201709 (t_id);
CREATE UNIQUE INDEX meteo_nantes_201709_pkey ON meteo_nantes_201709 (t_id);
CREATE UNIQUE INDEX meteo_paris_201709_pkey ON meteo_paris_201709 (t_id);
ALTER TABLE meteo_lyon_201709 REPLICA IDENTITY USING INDEX meteo_lyon_201709_pkey;
ALTER TABLE meteo_nantes_201709 REPLICA IDENTITY USING INDEX meteo_nantes_201709_pkey;
ALTER TABLE meteo_paris_201709 REPLICA IDENTITY USING INDEX meteo_paris_201709_pkey;
Vérifions l'effet de nos modifications :
pg10=# UPDATE meteo SET temperature=25 WHERE temperature<15;
UPDATE 150310
pg10=# SELECT count(*) FROM meteo WHERE temperature<15;
count
-------
0
(1 ligne)
La mise à jour a été possible sur la base de données principale. Quel effet cela a-t-il produit sur la base de données répliquée :
souscription=# SELECT count(*) FROM meteo WHERE temperature<15;
count
-------
75291
(1 ligne)
La mise à jour ne semble pas s'être réalisée. Vérifions dans les logs applicatifs :
LOG: logical replication apply worker for subscription "souscription"
has started
LOG: starting logical decoding for slot "local_souscription"
DETAIL: streaming transactions committing after 0/F4FFF450,
reading WAL from 0/F33E5B18
LOG: logical decoding found consistent point at 0/F33E5B18
DETAIL: There are no running transactions.
ERROR: logical replication target relation "public.meteo_lyon_201709" has
neither REPLICA IDENTITY index nor PRIMARY KEY and published relation
does not have REPLICA IDENTITY FULL
LOG: could not send data to client: Connection reset by peer
CONTEXT: slot "local_souscription", output plugin "pgoutput", in the change
callback, associated LSN 0/F33EC9B0
LOG: worker process: logical replication worker for subscription 17685
(PID 3743) exited with exit code 1
Les ordres DDL ne sont pas transmis avec la réplication logique. Nous devons toujours penser à appliquer tous les changements effectués sur l'instance principale sur l'instance en réplication.
souscription=# CREATE UNIQUE INDEX meteo_lyon_201709_pkey
ON meteo_lyon_201709 (t_id);
CREATE INDEX
souscription=# CREATE UNIQUE INDEX meteo_nantes_201709_pkey
ON meteo_nantes_201709 (t_id);
CREATE INDEX
souscription=# CREATE UNIQUE INDEX meteo_paris_201709_pkey
ON meteo_paris_201709 (t_id);
CREATE INDEX
souscription=# ALTER TABLE meteo_lyon_201709 REPLICA IDENTITY
USING INDEX meteo_lyon_201709_pkey;
ALTER TABLE
souscription=# ALTER TABLE meteo_nantes_201709 REPLICA IDENTITY
USING INDEX meteo_nantes_201709_pkey;
ALTER TABLE
souscription=# ALTER TABLE meteo_paris_201709 REPLICA IDENTITY
USING INDEX meteo_paris_201709_pkey;
ALTER TABLE
La réplication logique est de nouveau fonctionnelle. Cependant les modifications effectuées sur la base principale sont dorénavant perdues :
souscription=# SELECT count(*) FROM meteo WHERE temperature<15;
count
-------
75291
(1 ligne)
Réappliquons la modification sur la base pg10 :
pg10=# UPDATE meteo SET temperature=25 WHERE temperature<15;
UPDATE 0
Vérifions l'effet sur la base de donnée répliquée :
souscription=# SELECT count(*) FROM meteo WHERE temperature<15;
count
-------
0
(1 ligne)
souscription=# SELECT count(*) FROM meteo WHERE temperature=25;
count
-------
75291
(1 ligne)
Commentaires: